We provide the compute, runtime, and operational foundation required to run machine learning workloading reliably in production—without forcing you into proprietary tools.
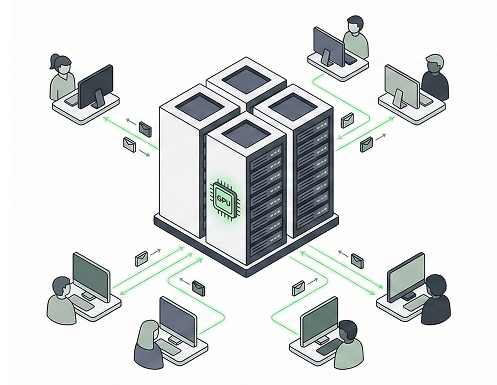
Support for NVIDIA H100, A100, and custom compute resources
Automatic scaling for training and inference workloads
PyTorch, TensorFlow, ONNX, JAX, and custom environments
Optimized runtimes for training and inference workflows
Automatic handling of libraries and custom dependencies
Track and manage runtime versions for reproducibility
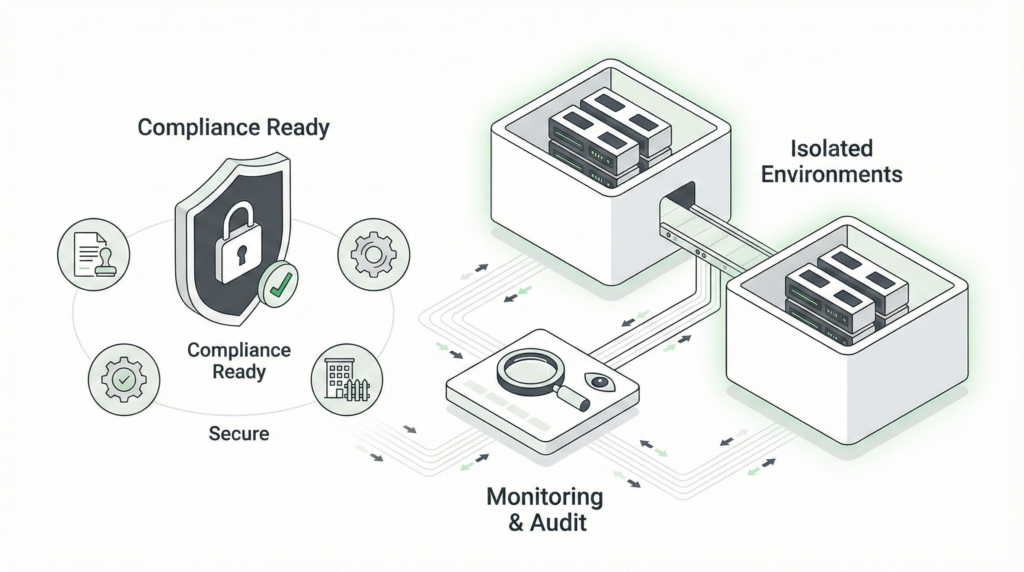
Dedicated compute with network isolation and encryption
HIPAA, SOC 2, and enterprise security standards
Complete visibility and audit trails for all operations
From Experimentation to Production
Define business problems, exploreavailable data, and formulate actionable ML use cases to drive innovation.
Designed to support your entire ML lifecycle, from ideation to enterprise deployment.
Cost-efficient for experimentation and development workloads
Infrastructure That Doesn’t Get in the Way
Use of favorite tools out-the-box (monitoring of Res CX as the frees)